Engineering organizations are hitting a planning wall that spreadsheets were not built for.
Headcount curves are familiar: slow ramps, predictable bands, and finance models that mostly work. AI tooling and API spend are different. Consumption is elastic, defaults change with every flagship model, and vendors can redraw the line between “included” and “metered” faster than a fiscal year unwinds. A budget that looked conservative at the end of last year can imply a run-rate crisis by mid-year - not because leaders were careless, but because token economics are not stable the way salary economics are.
I have been thinking about this alongside an older idea: planning as headcount versus tokens. Tokens buy leverage; they also buy volatility. The management problem is not only “how much to allocate” but how to govern a variable cost that responds to product releases, policy changes, and cultural defaults inside the engineering org.
This post is a general analysis: what is structurally unstable, what has shifted in the market recently, and what cost-control levers actually belong to leadership - not to individual engineers improvising at checkout.
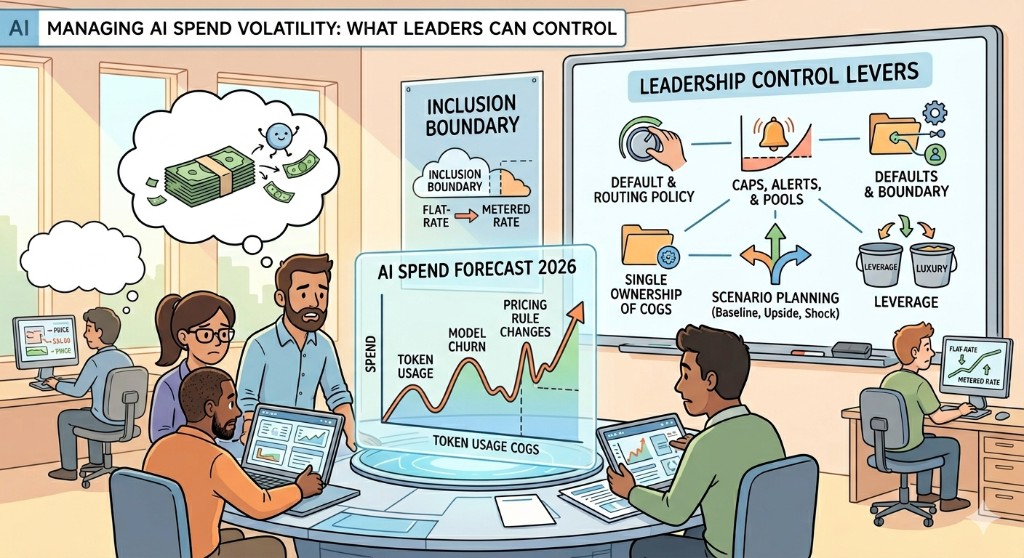
Why AI spend blows through forecasts
Three forces stack, and they rarely show up one at a time.
Model churn. When a materially better model ships, teams re-default to “best available.” Same workflows can consume more tokens per unit of output, or simply run longer because agents are more capable. Forecasts that assumed last quarter’s mix are wrong immediately.
Pricing rule changes. Subscription seats and “included” allowances are not permanent promises. Vendors can move work from bundled allowances to API-priced usage, introduce new tiers, or split pools (for example, everyday agent flows versus explicitly premium model routes). The integration pattern you standardized on can have different unit economics six months later.
Adoption success. The bitter joke is that the rollout worked. More engineers use the tools daily, more work moves agentic, and parallel spend appears (eval harnesses, CI experimentation, internal assistants) that never lived in the original budget line item.
Compared with headcount, this spend can step-change. That is the core structural issue.
Recent pricing context
As of early 2026, two widely discussed data points illustrate the volatility leaders are navigating.
Cursor publishes a clear model: separate usage pools (everyday agent flows versus usage billed at each model’s API rate), included monthly usage that rises with plan tier, and on-demand billing beyond included amounts at those same rates - documented in their account pricing materials. Team plans add enterprise features and, for some request paths, additional metering (for example, a per-token platform rate on certain non-Auto usage). The controversy in the market has been less about the existence of metering and more about expectation management: teams that treated the product like a flat fee discovered variable tails when they picked premium models, long contexts, or heavy agent use.
Anthropic / Claude has shipped new flagship models on a rapid cadence - good for capability, difficult for anyone freezing a twelve-month assumption. Separately, early April 2026 reporting described changes to how consumer subscription allowances apply to certain third-party agent integrations, with heavy usage shifting toward API-style metering and optional “extra usage” rather than riding entirely inside a flat monthly fee. Organizations that routed agent workloads through those integrations had to replan quickly. Whether a given workflow is “in” or “out” of subscription economics is now something to verify in current vendor docs, not assume from last quarter’s slide deck.
The leadership takeaway is not to litigate any single vendor decision. It is to recognize terms-of-trade risk: pricing and inclusion boundaries are moving objects.
What leaders can control despite volatility
Volatility is not the same as helplessness. The levers below are boring on purpose; they are the ones that actually move run rate.
1. Single ownership of AI COGS. Someone with budget authority should own seats, included usage, on-demand tails, and direct API projects in one weekly view. If finance sees a spike and engineering has four different buyers, you get theater instead of steering.
2. Defaults and routing policy. Culture is a billing control. If “always use the strongest model” is the unwritten rule, your forecast must assume premium pricing. Leaders can set org-wide defaults, approved model lists for classes of work, and escalation paths for exceptions - without turning every pull request into a committee.
3. Caps, alerts, and pooled enterprise terms. Use vendor dashboards, spend caps where available, and negotiated pooling before you need emergency reallocation. The goal is to catch drift in weeks, not at year-end true-up.
4. Scenario planning, not single-point budgets. Model at least three cases: baseline adoption, upside adoption, and a vendor shock quarter (inclusion boundary change or step-up in default model cost). If the plan only works in the baseline, it is fragile.
5. Separate “leverage” from “luxury” in governance. Not every workflow earns the most expensive route. Executive clarity on what is business-critical versus convenient reduces resentment when you throttle.
6. Reduce shadow procurement. Centralize purchasing and approved surfaces. Shadow IT in AI is almost always a signal that official paths are too slow or too constrained - not a moral failure, but a risk to consolidate.
7. Treat evaluation and automation as first-class spend. Harnesses and agent loops often bill separately from seats. If they are invisible in planning, they will be visible on the invoice.
None of this removes the need for judgment. It does move judgment from panic in June to design in January.
The strategic tension remains
Organizations will still face an uncomfortable binary when run rate diverges from budget: throttle (productivity and morale cost, shadow usage risk) versus refund the plan (competition with every other priority). The way to soften that choice is not perfect prediction. It is governance that assumes change.
If your AI strategy depends on vendor prices staying still, it is not a strategy. It is a bet.
Questions worth putting on a staff agenda
What is our default model policy for routine work versus high-risk work, and when did we last revisit it?
If our largest provider changed inclusion rules next month, which workflows would break first on cost, and which on capability?
Those answers belong in leadership systems, not in hallway rumors.